TLDR: MapAnything is a simple, end-to-end trained transformer model that directly regresses the factored metric 3D geometry of a scene given various types of inputs (images, calibration, poses, or depth).
Abstract
We introduce MapAnything, a unified transformer-based feed-forward model that ingests one or more images along with optional geometric inputs such as camera intrinsics, poses, depth, or partial reconstructions, and then directly regresses the metric 3D scene geometry and cameras. MapAnything leverages a factored representation of multi-view scene geometry, i.e., a collection of depth maps, local ray maps, camera poses, and a metric scale factor that effectively upgrades local reconstructions into a globally consistent metric frame. Standardizing the supervision and training across diverse datasets, along with flexible input augmentation, enables MapAnything to address a broad range of 3D vision tasks in a single feed-forward pass, including uncalibrated structure-from-motion, calibrated multi-view stereo, monocular depth estimation, camera localization, depth completion, and more. We provide extensive experimental analyses and model ablations demonstrating that MapAnything outperforms or matches specialist feed-forward models while offering more efficient joint training behavior, thus paving the way toward a universal 3D reconstruction backbone.
Qualitative Results
We visualize MapAnything results on a variety of image-only inputs. Try it out yourself! - 🤗 Hugging Face Demo
Qualitative Comparison
We compare MapAnything with VGGT and π³ on various scenes using only images as input.
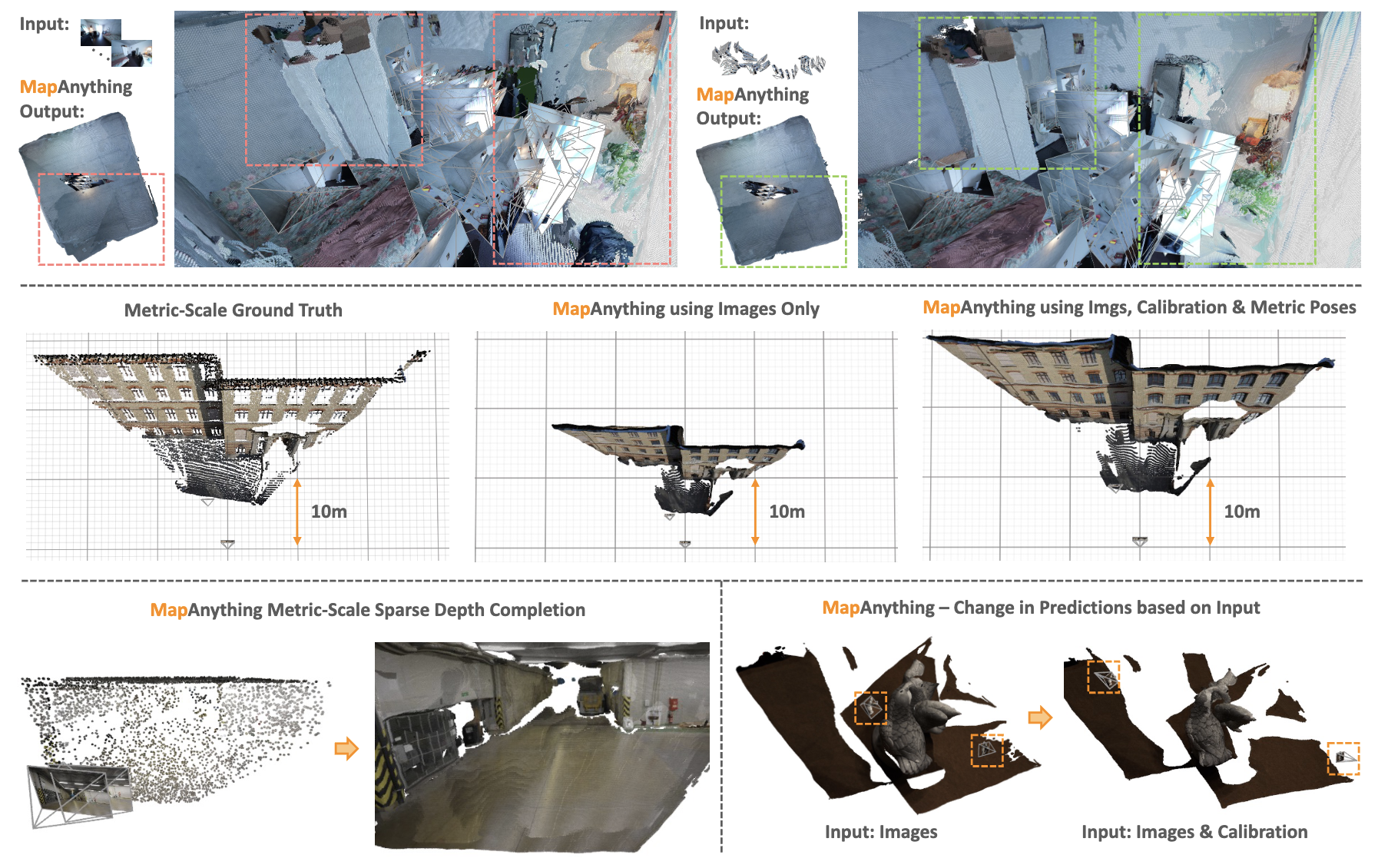
Auxiliary Geometric Inputs
MapAnything can leverage various geometric inputs including camera calibration, poses, and depth to improve 3D reconstruction quality across different tasks.